Twitter APIでデータを集める。APIは JavaScriptや PHPからアクセスすることができる。最新版のRであれば直接アクセスすることも可能だ。今回は安保法制賛成派(右翼)と反対派(左翼)でそれぞれ4人を選びネットワークを作った。
TwitterデータからSIFファイルを作る。SIFファイルはusername1 follow username2のような形式をしている。
Cytoscapeに読み込ませて、並べ替え(Spring Embedなどを使う)て概要を掴む。データが大きくなると並べ替えに時間がかかるので、手作業で1名からフォローしているだけ、されているだけの人を取り除いた。
CytoscapeからGMLファイルを書き出す。
Rで読み込む。予めライブラリigraphを読み込んでおく。library(igraph) と read.graph(,format=”gml”)
コミュニティを調べるために下調べする。edge.betweenness.communityなどを使うが、いくつかの違った分類法を使うことができるが、方法によって精度や計算時間などに違いがあるらしい。
コミュニティを分割する。コミュニティの数が集約するまでNの数を増やして行く。詳しい事は分からないが、影響のないエッジを消していっているいるらしい。community.to.membership(g,data$merge,step=N)
データセットを作成する。data.frame(membership=d$membership,label=V(g)$label,betweenness=betweenness(g),closeness=closeness(g))
データセットを書き出す。write.table(df,file=”data.txt”)
エクセルなどに取り込んで betweennessで並べ直す。数値が大きければ中心にあることが分かる。
属性テーブルに編集し直すと(ID名 = メンバーシップ)Cytoscapeに取り込むことができる。ファイルの先頭に1行加えておくこと。それが属性名になる。
新しいビジュアルスタイルを加える。 Node Shapeを選び、Discrete Mappingを選ぶと属性ごとに色分けができる。Betweennessやclosenessを属性を利用して中心に近い円ほど大きく表示する事もできる。
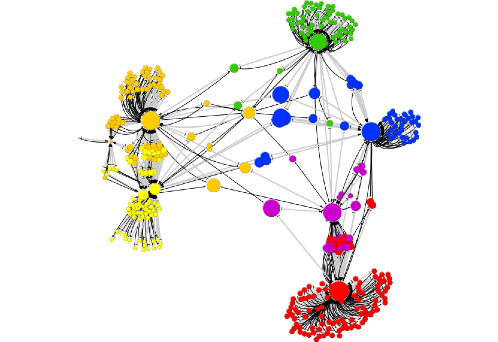
手作業で並べたもの。大体正しくグループ分けされていることが分かる。ただし、異なるグループが共有されているアカウントはランダムにグループ分けされているらしい。黄色とオレンジが安保法案反対派(左翼)で、残りが安保法制賛成派(右翼)に属する。右翼は結びつきが薄いのでそれぞれ別グループを形成している。
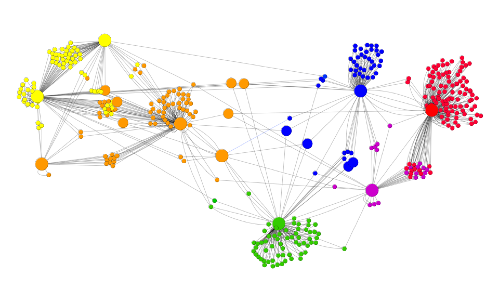
機械的(Spring Embed)に並べ替えたもの。