最近、ちょっとうんざりするような出来事があった。頂いたコメントをこちらが勘違いしたようなのだが、ダイレクトメッセージで縷々「私が言ったことと違う」ということをつづられた。確かに間違えたのはこちらが悪かったのかもしれないのだが、記録として出したいと申し出ると「もう、心理的にしんどいから嫌だ」となった。
ブログは活字のように見えてしまうので、議論の結果を残すのは「最終的な結論や事実ではなく、途中結果なのですよ」ということを示したいという意図がある。そういう作業をしておかないと、ここに書いてあることを鵜呑みにする人が出てくる。だが、これを申し出るときに「典型的な日本人は受けてくれないだろうなあ」と思っていた。案の定そうなったのでちょっとうんざりしたのだ。
なぜ、公開で意見を表明するのがしんどいのかということを取材するいい機会かなあと思ったのだが、それを普通の日本人に考えさせるのは不可能だろうとも思った。そこで勝手に想像するしかない。理由を三つ考えた。
第一の理由は日本人が異質なものに囲まれた経験がなく、他人に自分を分からせるという経験してこなかったことが挙げられる。さらに同調圧力が強く「同じ」であることが暗黙の前提になっている。つまりそもそも自分と完全に考えが一致しない人と接するのが苦手なのだ。
第二の理由は個人が持っている「見られたい自分像」がある。たいていの人は「周りに合わせる調和的な自分」が美しいと考えており、反論することで「反抗的だ」という印象を与えることを極端に嫌う。反抗的だと思われないにしても「言い出したんだからあなたが責任を取ってね」といわれるのが嫌なのだろう。このように「言っていること」よりも「誰が言ったか」という文脈が大切な文化でありなおかつ「誰も言わないのにそうなった」ということが好まれるので反論がしづらいのだ。
最後の理由は文脈だ。Twitterは多くの人が読んでおりどう解釈されるか分からない。これがもう一つの文脈である。なので「大切になればなるほど」「自分の人格の確信に近ければ近いほど」非公開の議論を求める傾向がある。ある意味告白に近いので「完璧に全く誤解がないように」伝えなければという気持ちになり、何回も推敲を重ねた挙句「やっぱり理解されないかもしれない」となってしまうのではないだろうか。
つまり事実を取り扱えない文脈依存と同質性のおかげで自分の意見が言えない。そこで「とてもしんどい」ということになってしまうのだろう。
ここまで「普通の日本人は」と書いてきた。ずいぶんと鼻に付く表現なのだがこれには理由がある。過去に付き合った日本人の中にも自分をうまく伝えられる人たちがいる。彼らの特徴は外国文化(といっても主にアメリカ文化になってしまうのだが)に接したことがあるという点である。だが、中国人やインド人のエンジニアにもある傾向なので、外国文化を知っていると、他人に自分を伝える技術を身に付けられるのではないかと思う。これを「アサーティブネス」と言っている。
アサーティブジャパンは、アサーティブとは自己主張を意味するが、自分の意見を押し通すことではないと説明している。日本語の訳語はないようだ。つまりわがままにならない自己主張だ。
海外経験のないビジネスマンでも、プレゼンテーションを担う企画職がアサーティブさを持っている場合がある。プレゼンターは自分たちのサービスを知らない相手に売り込むというミッションがあるので「相手にわからせる」訓練が行われるのではないかと考えることができる。
つまり日本人も自己主張ができるようになるということだ。日本人が自分を分からせる技術を持たないのは、単に家庭や学校で習わず職業的にも訓練されないからに過ぎないのではないだろうか。
誰もがアサーティブさを習うべきだとは思わないのだが、少なくとも誰かの意見を読んでそれが100%自分と同じだと思い込まないほうが良いと思うし、だれかが全くの誤読なしに自分の意見を受け入れてくれるとは思わないほうがよい。「それが自分と必ずしも同じではない」と分かると心理的なしんどさが生まれてストレスになるからである。だが、自分と全く同じ考えを持った人などいないわけで、そもそも誤読される可能性を前提に何かを言うべきだということになる。
さてTwitterで議論がかみ合わないことが多いのは、そもそも同質でない上に、異質なものと情報交換したり議論ができないことによるのかもしれない。日本人は公共空間では極力他人を当てにしないで生きている。これは異質なものとうまくやってゆく訓練を一切受けずに街を歩くからだろう。例えばコンビニでドアを開けると嫌な顔をされることが多い。それは「私にかまうな」ということである。異質なものはすべて敵なのでちょっとした親切も受けられないのだ。だが、Twitterはたまたまパーソナルなスマホ空間でやり取りされることが多いのでパーソナル空間に他者が土足で踏み込んでくるというような経験になるのではないだろうか。そこに不快さが生まれる。
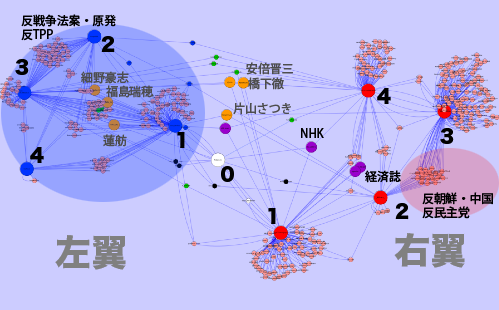
さて現在日本には右と左という2つの極端な政治的流派があるとされているのだが、実は同質なのではないかと思うことがある。どちらも自分の中にある考えをまとめて他人に説明することができない。そこに不愉快な他者が入り込み「しんどくて不安」な気分になる。一方、不愉快な他人を排除したいという気持ちはみんなが共通で持っているので、敵を設定して争っている限りは同調圧力のない一体感を感じることができるのではないだろうか。
もっとも、アサーティブさというのは現在足りていない技術なので、ここをうまく突けば需要のある文章が書けるなあとは思う。実際に大衆扇動家というのはこのあたりの技術に長けているのではないだろうか。